问题描述
近期使用Adobe Acrobat XI软件识别一张长图中的文字时,报错:Acobat无法在本页面上执行OCR识别,因为本页面的大小超过了最大的页面大小45英寸 * 45英寸。
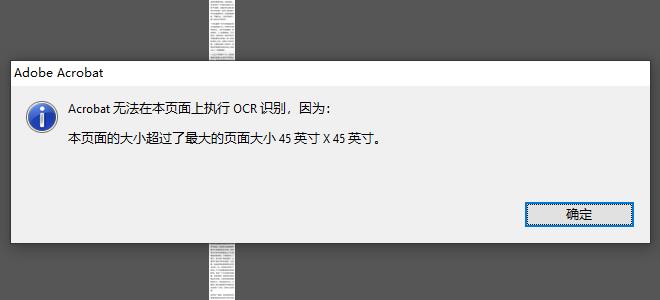
解决过程
既然是由于图片大小过大导致,那我们直接将图片裁剪成若干个小图片即可,这里我们使用PhotoShop的切片工具来切图。
大图切成若干个小图方法
- 用PS打开大图
2.【选做项】如果图片中的文字比较模糊,分辨率不高时,用QCR识别后的文字错误会比较多。这时我们可以用锐化工具将图片处理一下:点击菜单【滤镜】–> 【锐化】 –> 【智能锐化】打开智能锐化操作窗口,根据锐化效果调节【半径】参数,调节好后点击【确定】即可。 - 查看图片大小,根据大小我们需要换算出切换成几份小图。点击菜单【图像】 –> 【图像大小】,将文档大小的参数单位改为“英寸”,将高度除以45得到需要切成几份。
- 点击工具栏的【切片工具】,在图片上右击选择【划分切片】,选择“水平划分为”,将上一步计算得出的切片数填入“个纵向切片,均匀分隔”,点击【确定】,之后调节切片的分割线,将在文字上的分割线拖动到空白处。
- 按下ALT+SHIFT+CTRL+S,调出储存为web所有格式的操作面板,保存品质选100,保存即可。
识别图片中的文字
- 选择切分的图片,右击选“在Acrobat中合并文件”打开。
- 打开【工具】–> 【文本识别】 –> 【在本文件中】,选择“所有页面”,【确定】
- 识别后,选择【文件】–> 【另存为其它】–> 【Word文档】或【更多选项】中的【纯文本】保存。
- 之后打开保存的文档,仔细比对内容,将识别错误的内容改正。
转载请注明:半亩方塘 » Adobe PDF识别长图文字报错本页面的大小超过了最大的页面大小45英寸
赞 (8) 支付宝扫码打赏
支付宝扫码打赏 微信扫码打赏赏
微信扫码打赏赏
支付宝扫码打赏微信扫码打赏赏